
搜索引擎技术方案
- 搜索引擎方案
- 功能需求背景:
----有搜索引擎需求
- 功能需求
- 提高查询效率,关键词全文检索。
- 不需要访问多次数据库,只能一次数据库查询。
- 准确关键词全文检索。
- 由于查询功能效率较差,等待时间过长,数据量大以及多租户多用户关系查询。
- 需求分析
- 提高用户体验,查询效率,关键词全文检索。
- 准确性查找关键词全文检索数据,不使用模糊查询。
- 多租户与用户关系:多对多,多对一,一对多。
- 根据多租户与用户关系来关键词全文检索。
- 解决方案(建议使用lucene框架搜索引擎)
方案一:(推荐)
- 第一步:定义一个租户标识作为索引库(即服务器盘符文件夹路径)。
- 第二步:dataId+用户标识=idField(索引库id)。
- 第三步:指定检索字段拼接于nameField(索引库name)
- 第四步:对索引库增删改。
- 第五步:全文检索出该租户下所有符合的关键词检索(可以设置检索的前几条)。
- 第六步:通过用户标识过滤用户数据,从idField(索引库id)解析dataId保存数据集。
- 第七步:通过dataId数据集去数据库查找对应数据(id查询结果集)。
- 第八步:查询结果集返回页面查询。
方案二:
- 第一步:定义一个索引库(即服务器盘符文件夹路径)。
- 第二步:租户标识+dataId+用户标识=idField(索引库id)。
- 第三步:指定检索字段拼接于nameField(索引库name)
- 第四步:对索引库增删改。
- 第五步:全文检索出该租户下所有符合的关键词检索(可以设置检索的前几条)。
- 第六步:通过租户标识过滤租户数据,通过用户标识过滤用户数据,从idField(索引库id)解析dataId保存数据集。
- 第七步:通过dataId数据集去数据库查找对应数据(id查询结果集)。
- 第八步:查询结果集返回页面查询。
- Lucene索引结构图解
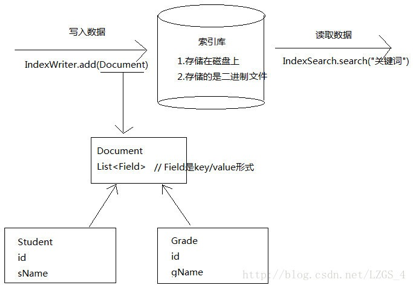
- Lucene全文检索说明
- 索引库的增、删、改是由indexWriter来操作的
- 同一个时刻内。同一个索引库,仅仅能同意一个indexWriter操作
- 当IndexWriter创建完毕以后,indexwriter所指向的索引库就被占据了。仅仅有当indexWriter.close时。才干释放锁的资源
- 当一个新的indexWriter想拥有索引库时,原来的indexWriter必须释放锁
- 仅仅要索引库中存在write.lock文件,说明上锁了
- indexWriter.close有两层含义:1. 关闭IO资源; 2.释放锁
- 能够设置非常多个索引库.
- 索引库能不能合并起来?
假设是内存索引库
Directory ramDirectory = new RamDirectory(Directory d);
这样就能够把一个索引库放入到内存索引库中
利用IndexWriter.addIndexesNoOptimize方法能够把非常多个索引库进行合并操作.
- 应用程序能不能在内存中和索引库进行交互.
- 搜索引擎实现
- 索引库写入信息
public void testCreateIndex() throws Exception{
/**
* 1、创建一个student对象,而且把信息存放进去
* 2、调用indexWriter的API把数据存放在索引库中
* 3、关闭indexWriter
*/
// 创建一个Student对象。而且把信息存放进去
Student student = new Student();
student.setId(1L);
student.setName("张三");
// 调用indexWriter的API把数据存放在索引库中
/**
* 创建一个IndexWriter
* 參数三个 1、索引库, 指向索引库的位置 2、分词器
*/
// 创建索引库
Directory directory = FSDirectory.open(new File("./indexDir"));
// 创建分词器
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_30);
IndexWriter indexWriter = new IndexWriter(directory, analyzer, MaxFieldLength.LIMITED);
// 把一个student对象转化成document
Document document = new Document();
Field idField = new Field("id",student.getId().toString(),Store.YES,Index.NOT_ANALYZED);
Field nameField = new Field("name",student.getName(),Store.YES,Index.ANALYZED);
document.add(idField);
document.add(nameField);
indexWriter.addDocument(document);
// 关闭indexWriter
indexWriter.close();
}
- 索引库读取信息
public void testSearchIndex() throws Exception{
/**
* 1、创建一个IndexSearch对象
* 2、调用search方法进行检索
* 3、输出内容
*/
// 创建一个 IndexSearch对象
Directory directory = FSDirectory.open(new File("./indexDir"));
IndexSearcher indexSearcher = new IndexSearcher(directory);
// 调用search方法进行检索
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_30);
QueryParser queryParser = new QueryParser(Version.LUCENE_30,"name",analyzer);
Query query = queryParser.parse("张"); // 要查找的关键词
TopDocs topDocs = indexSearcher.search(query, 2); // 前两条
int count = topDocs.totalHits; // 依据关键词查询出来的总的记录数
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
List<Student> studentList = new ArrayList<Student>();
for(ScoreDoc scoreDoc:scoreDocs){
float score = scoreDoc.score; // 关键词得分
int index = scoreDoc.doc; // 索引的下标
Document document = indexSearcher.doc(index);
// 把document转化成Student
Student student = new Student();
student.setId(Long.parseLong(document.get("id"))); // document.getField("id").stringValue()
student.setTitle(document.get("name"));
studentList.add(student);
}
for(Student student:studentList){
System.out.println(student.getId());
System.out.println(student.getName());
}
}